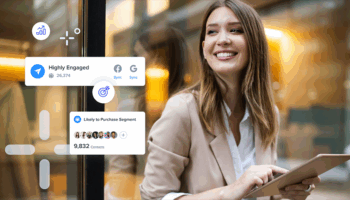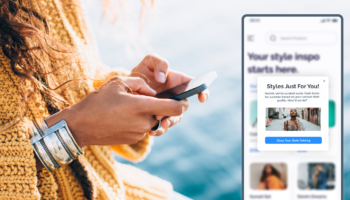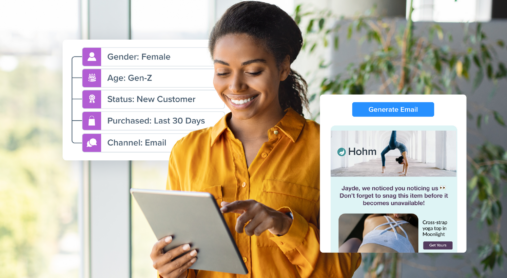

Imagine having a tireless, intelligent ally that can transform your marketing strategies overnight—that’s the promise of AI assistants. These advanced tools are not just changing the rules; they’re rewriting the entire playbook for how brands engage with their audiences, driving efficiency, creativity, and personalization like never before. AI assistants are transforming how marketers work, enhancing their ability to make smarter decisions and execute campaigns faster and more precisely.