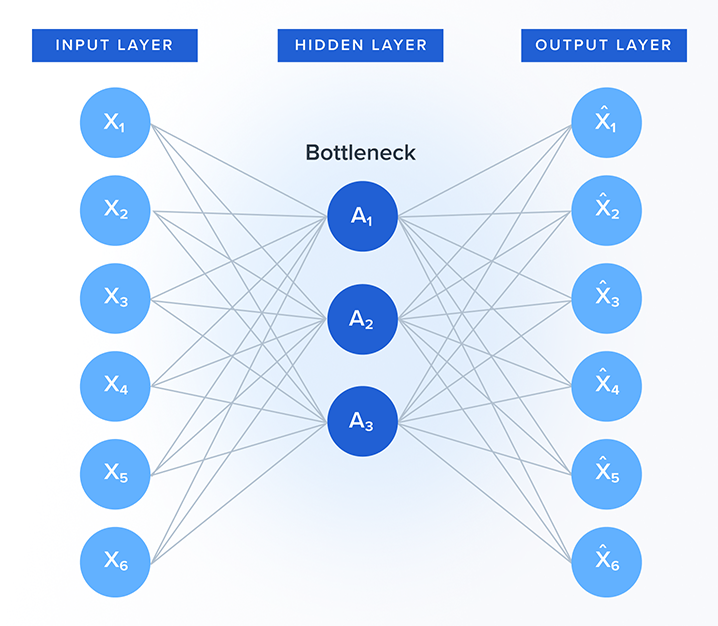
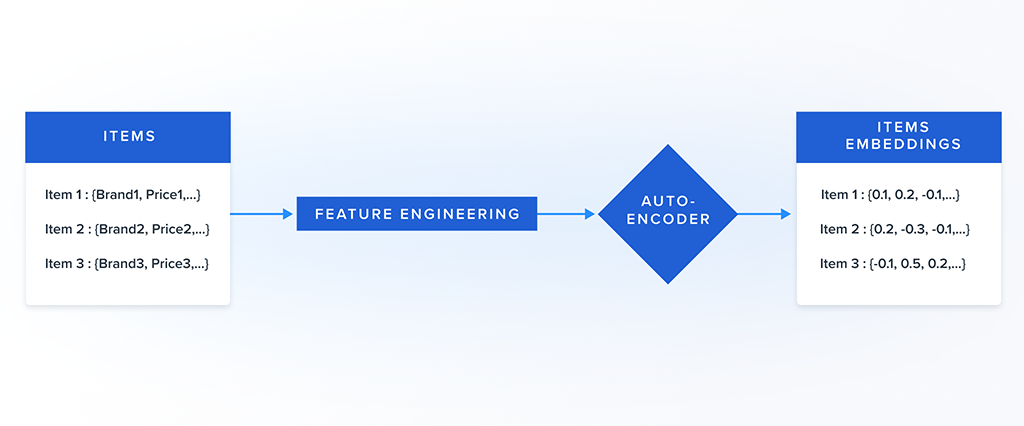
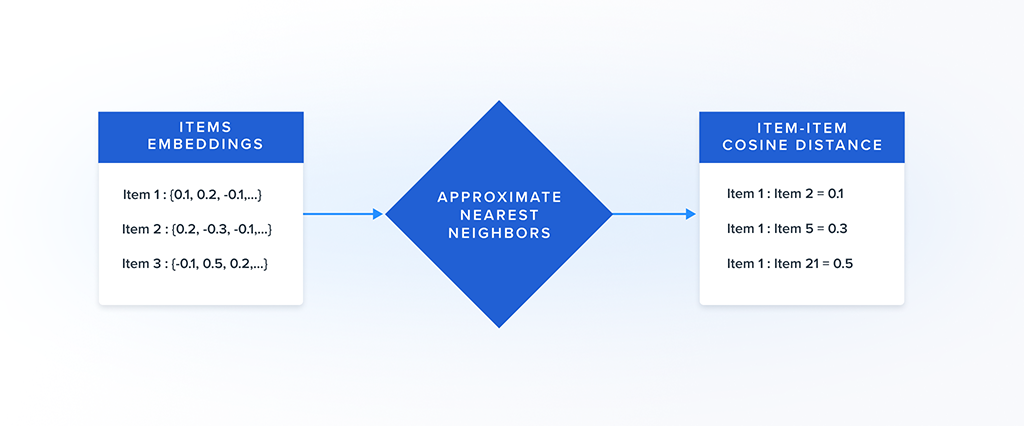
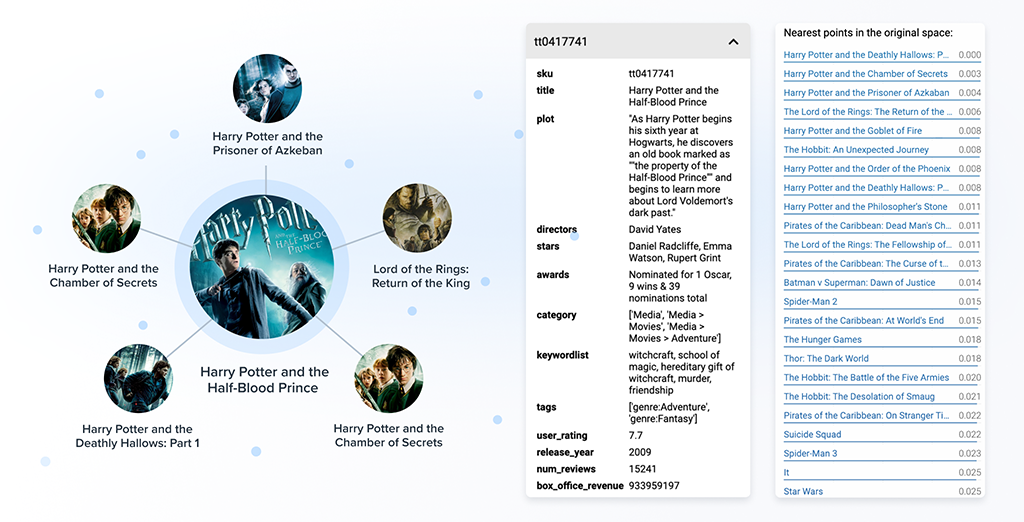
The core purpose of the Auto-encoder is to transform the mixed-datatype attribute information of an item into a fixed-length numeric representation called the embedding. The item embeddings can then be used to find similar items by a nearest neighbor search.
An item’s attributes can be of various data-types. Attributes like price and user rating are numeric, attributes like title and description are textual, attributes like brand and shipping method are categorical and attributes like tags are a list of keywords. However, the Auto-encoder can only take in numeric input, hence we need to transform all types of data into numeric types.
We classify item attributes into several different types: numeric, array-of-string, textual and categorical. Each data-type is feature engineered into a valid input for the auto-encoder as follows:
A. Numeric Attributes
Numeric attributes don’t need much transformation. We simply impute empty values with mean or median and then normalize the values so that they have zero mean and unit standard deviation.
B. Categorical Attributes
String attributes are usually categorical values that contain either a single word or phrase for each item. Such attributes are handled with eigen-categorical-encoding where the category is represented by a real number.
C. Textual Attributes
An item may have several textual attributes like title, description, etc. We utilize Natural Language Processing (NLP) models to convert the text into numeric embeddings. These embeddings are fed into the auto-encoder as input.
D. Array-of-String Attributes
Array-of-string attributes such as tags or keywords are values consisting of an array of words or phrases. We utilize a top-k based one-hot-encoding that is used as an input to the auto-encoder.
The transformed attribute values for all items are then passed into the auto-encoder that learns a fixed-length numeric representation for each item (embedding).