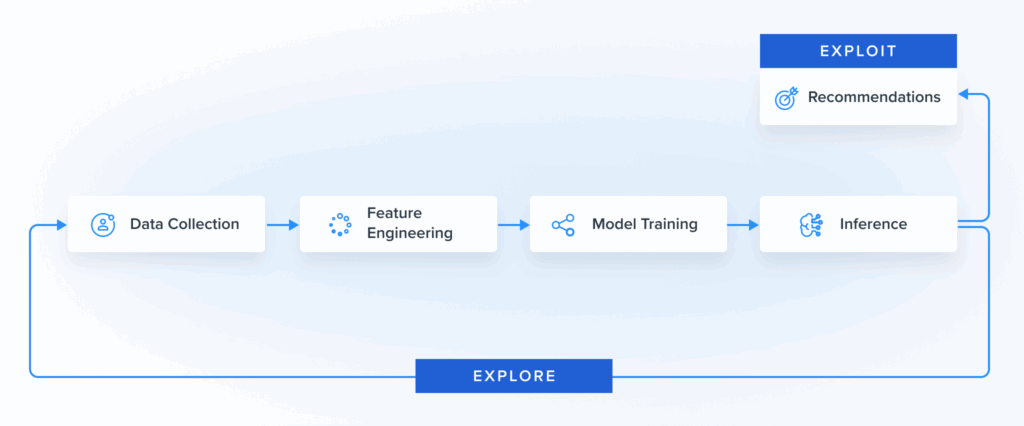
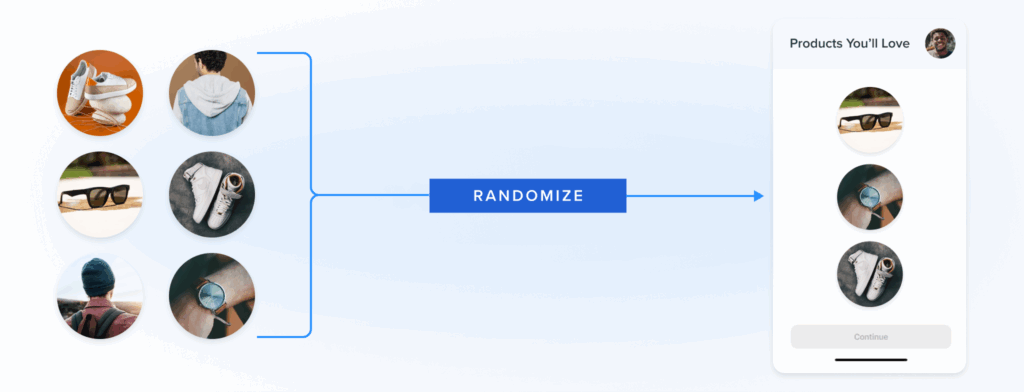
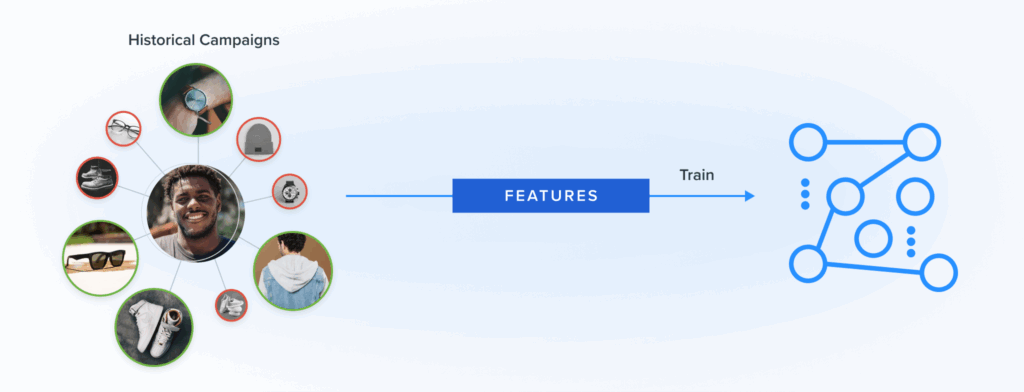
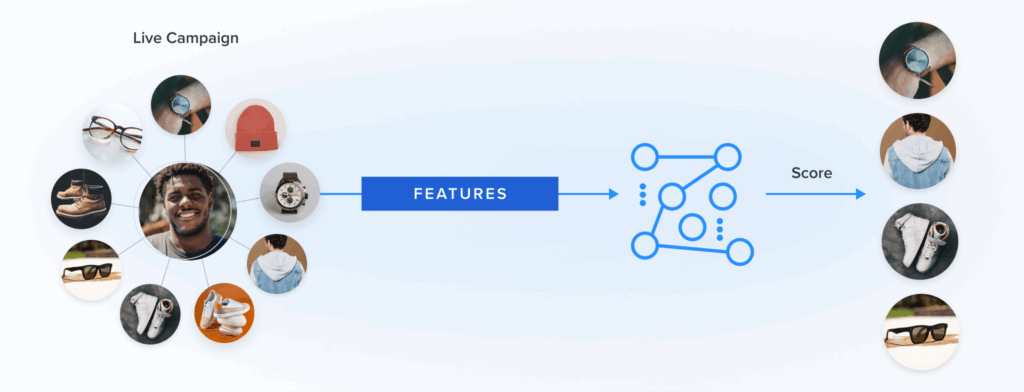
Last month, we announced the expansion of the Blueshift Recommendations Studio that gives every marketer the power of AI to drive intelligent and highly personalized recommendations. This expansion includes the launch of 100+ pre-built AI marketing recipes, preloaded with configurations for common campaigns, like abandoned carts, price drops, newsletter feeds based on affinities, and cross-merchandising based on the wisdom of the crowds.
Today’s blog post is the first of many that will provide an under-the-hood view of how the expanded Recommendations Studio works. Today’s post is written by Anmol Suag, senior data scientist at Blueshift. You can also read a follow-up post about using Auto-encoders to find similar items to recommend.