
The modern data stack promises a simple narrative: centralize all your data in a warehouse, then use a flexible composable CDP or Reverse ETL tool to push that data to your marketing channels. It’s an appealing story, but it overlooks the fundamental architectural requirements for effective, real-time marketing activation. For brands serious about activating first-party data, a purpose-built architecture delivers what actually matters: speed, reliability, low cost, and marketing autonomy. Let’s break down why.
TL;DR: Warehouse-First vs Purpose-Built CDP (What Actually Matters)
Warehouse-first stacks are great for analytics—but they’re batch by design. A purpose-built Customer Data Platform like Blueshift is built for real-time activation: millisecond ingestion, identity at write-time, and embedded AI that decides & delivers the next best action across channels.
- Latency gap: CDP processes events in <100ms and activates in <5s; warehouse + reverse ETL typically adds 15–60+ minutes.
- Data model: CDP uses a dual store + interaction graph for instant lookups and 1:1 personalization; warehouses optimize for large analytical scans.
- Identity & state: CDP resolves identities at write-time, keeping a live single customer view; warehouse models rely on batch joins.
- Built-in decisioning: CDP includes AutoML for predictive audiences, recommendations, and send-time/channel optimization; composable stacks move data but don’t decide.
- Marketing autonomy: No-code journeys, derived attributes, and guardrailed agentic AI → fewer tickets, faster launches.
- Dual-zone strategy: Use the warehouse as system of record (“think slow”) and the CDP as system of engagement (“think fast”)—connected bi-directionally.
- Economics: Composable = stacked margins (warehouse + reverse ETL + engagement). CDP consolidates activation and lowers total time-to-value.
The Latency Gap: When Minutes Cost Millions
The most critical difference between the two approaches is the delay between a customer action and a marketing reaction. The warehouse-first model is fundamentally batch-oriented. An event must be ingested, loaded into the warehouse, processed, queried by a Reverse ETL tool, and synced to a marketing platform. This multi-step process results in a total delay of 15 to 60 minutes.

In contrast, a real-time Customer Engagement Platform (CEP) such as Blueshift, is built for real-time streaming data. The event processing pipeline is designed for low latency, processing events in under 100ms. According to a Forrester study, brands that leverage real-time data for personalization see an average 20% increase in revenue. When a customer abandons a high-value cart, that massive time difference between batch and real-time is the gap between revenue recovery and a lost sale. Real-time activation isn’t a luxury; it’s a core driver of conversion.
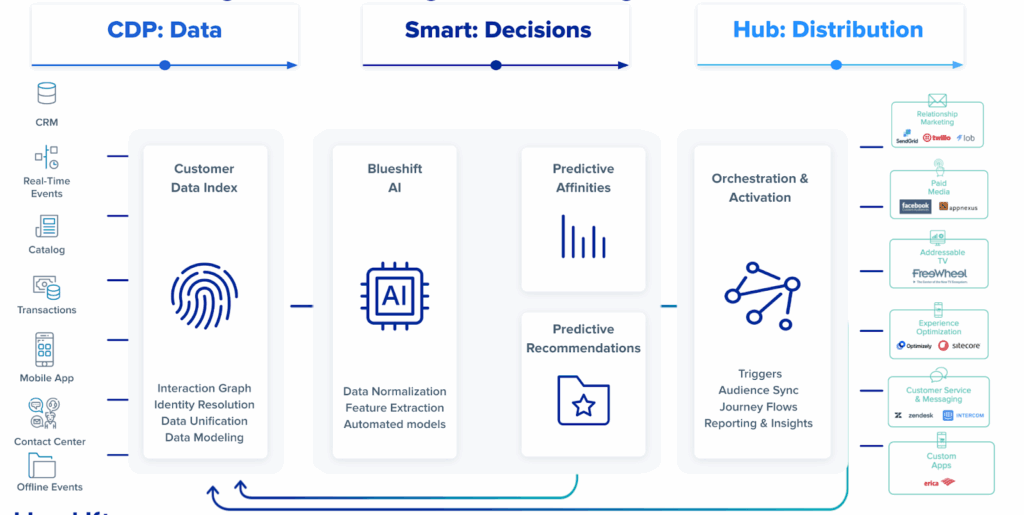
Why is a Purpose-Built Data Model Better for Marketing Activation?
Data warehouses are optimized for analytical queries: scanning billions of rows to find trends. But marketing activation requires different access patterns: complex audience segmentation and instant, single-user lookups for personalization. As we explain in our core article, What is a Customer Data Platform?, a CDP’s primary function is to unify customer data for marketing purposes.
Blueshift’s architecture was designed for these specific needs from day one. It starts with a Lambda Architecture that combines real-time and batch data processing, allowing the platform to react to immediate customer intents while also leveraging their long-term interests.
At the heart of this is a patented Interaction Graph. Instead of just storing data in tables, Blueshift connects customers to entities like products, channels, and locations. Every customer interaction creates new “edges” in this graph, which can then be used for sophisticated AI-based personalization. This graph-based data model is far more powerful for understanding relationships than the relational tables in a data warehouse. It’s the foundation for the platform’s AI decisioning and avoids the performance bottlenecks of trying to force an analytical database to handle a complex operational workload.
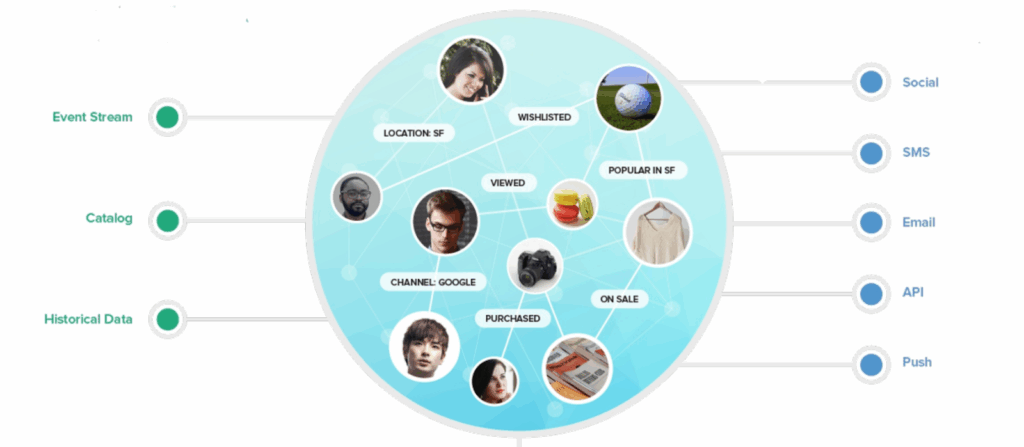
How Does Batch Processing Affect Identity Resolution?
Effective marketing requires a consistent, unified view of the customer and their journey. This is where the batch nature of the warehouse-first CDP model creates challenges.
In the warehouse model, unifying profiles requires running periodic batch jobs. A purpose-built CDP like Blueshift, on the other hand, performs identity resolution and data unification at write-time, which means the profiles are always up to date and ready to be activated with up-to-the-second data. This means no more messaging the same person with two different profiles. You can act immediately on critical lifecycle changes, trusting that every campaign is working with a perfectly unified, up-to-the-second view of the customer.
Why is a Built-in AI Engine Superior to a Data Mover?
A composable CDP is a data mover; its job is to sync audiences from a warehouse to another tool. This leaves the burden of intelligence, i.e. predicting what a customer will do next, entirely on your data science team.
In contrast, Blueshift has built-in AI decisioning: It’s an AI-driven decision engine built to determine the right content, timing, and channel for each customer. The platform includes a homegrown AutoML (Automated Machine Learning) application that powers:
- Predictive Audiences: To select the best customers to target for any campaign.
- Predictive Recommendations: To determine the right product or content for each user based on their journey.
- Predictive Engage Time & Channel-of-Choice: To optimize when and where to deliver the message.
This provides immense leverage. Instead of just segmenting on past behavior, you are activating data based on predicted outcomes like purchase, churn, or engagement. This intelligence is an integrated part of the platform, not a separate, resource-intensive project that your teams have to build and maintain from scratch.

How Do the Two Approaches Compare on Agility and Flexibility?
The most sophisticated enterprise data strategies no longer force a choice between a data warehouse and a CDP. Instead, they embrace a “Dual Zone” architecture, recognizing that different parts of the business have different data needs.
- Zone 1: The Data Ecosystem (Think Slow). This is the world of Enterprise IT, centered on the data warehouse (Snowflake, BigQuery, etc.). It is the system of record, designed for governance, analytics, and “macro decisions” that require a deep historical view.
- Zone 2: The Experience Ecosystem (Think Fast). This is the world of Marketing and customer experience, centered on real-time activation. It is the system of engagement, designed for the “micro-decisions” needed to personalize an interaction in the moment.
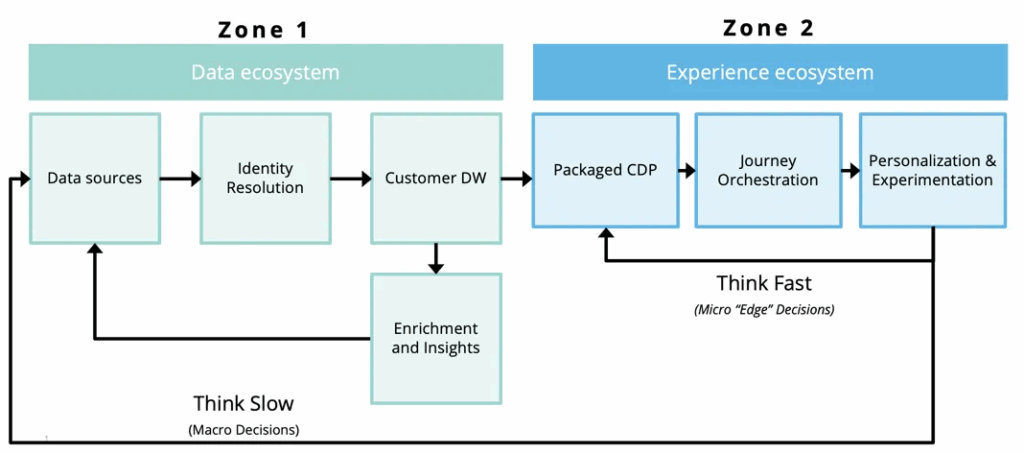
(The Dual Zone Architecture, illustrating the separation of slow and fast data ecosystems. Image courtesy of David Chan)
The warehouse-first approach tries to force the “slow” Zone 1 architecture to perform “fast” Zone 2 tasks, which leads to the latency and agility gaps.
As detailed in our other article, CDP vs. Data Warehouse: The Core Differences, the two platforms are built for different purposes and work best when used together.
Blueshift is purpose-built as the “packaged CDP” for the Zone 2 Experience Ecosystem. It bridges the two zones through native, bi-directional connectors that unify the rich, historical “golden records” from the Zone 1 warehouse with in-the-moment behavioral data captured directly in Zone 2. This allows marketers to activate a complete, 360-degree customer view without compromising on speed.
This strategy provides the best of both worlds. It respects the investment and governance of the central data warehouse while empowering marketing teams with a best-in-class, real-time activation and AI decisioning engine.
What are the Economic Costs of a Composable Marketing Stack?
The composable model creates a “stacked margin” problem, where you pay for multiple vendors in a single workflow. Assume your use-case is to send personalized emails to your users, your workflow stack would be:
- Composable Stack: Public cloud + Warehouse + Composable CDP + Engagement Platform + Delivery
- Integrated CDP: Public cloud + Activation CDP (Blueshift) + Delivery
This multi-vendor approach leads to escalating costs, with users reporting price jumps of 2x-3x and getting “priced out” at renewal. Blueshift’s integrated model offers a more predictable and efficient Total Cost of Ownership.
Why Does the Warehouse Model Create an Intelligence and Agility Gap?
The most persistent complaint from marketers using composable CDPs is being blocked by technical requirements, primarily the need for SQL knowledge. This transforms marketing-owned processes into engineering projects, creating bottlenecks that slow campaign execution. Blueshift is designed to close this skills gap. Instead of requiring SQL, it provides marketers with:
- No-Code Studios & AI Assistants: Intuitive interfaces for building audiences, journeys, and even generating personalized content with Generative AI.
- Stateful Logic & Derived Attributes: Marketers can model complex customer lifecycles and create new data fields (e.g., “last purchase category”) with a few clicks, a task that would require a data engineer in the warehouse-first world.
- Agentic AI: Beyond simple predictions, Customer AI Agents can operate and optimize marketing autonomously: generating creative, running experiments, and re-allocating traffic to winners without manual intervention.
Comparison: Purpose-Built CDP vs. Warehouse-First Approach
| Comparison trait | Blueshift (Purpose-Built CDP) | Warehouse-First |
| Architecture Type | Integrated, real-time platform with specialized microservices for each function. | Composable, unbundled stack of separate tools centered around a data warehouse. |
| Core Data Model | Dual-datastore: Key/Value store for instant lookups and a Patented Interaction Graph for AI/personalization | A single, centralized Cloud Data Warehouse using relational tables. |
| Data Ingestion | Real-time event streaming via Kafka/Pulsar with ingestion latency under 150ms. | Batch-oriented loading where data must first land in the warehouse on a schedule. |
| Event-to-Activation Latency | Under 5 seconds (<100ms per event) | 15 – 60+ minutes (sum of warehouse load, model run, and sync times). |
| Identity Resolution | Integrated and performed in real-time at write-time as data arrives, ensuring profiles are always updated and ready to activate. | Requires separate batch SQL jobs or complex, slow query-time joins in the warehouse. |
| AI & Decisioning | Integrated, out-of-the-box AutoML for predictive audiences, recommendations, and timing optimization | Requires a separate, bring-your-own model. Reverse ETL tools are data movers, not decision engines. |
| Schema Management | Flexible schemas with no upfront modeling required; new attributes are available for activation almost immediately | Strict, predefined schemas that require data engineering to update tables, models, and mappings. |
| Marketing Agility | High autonomy. Marketers can launch complex, data-rich campaigns without engineering dependency. | Dependent on data/engineering teams to model data in the warehouse and configure new syncs. |
In closing
The question isn’t “Can you do marketing with a warehouse?” You can. The question is “What is the opportunity cost?” Every minute of latency, every complex query, and every engineering ticket is a marketer blocked and revenue lost. A purpose-built, AI-powered architecture designed for the Experience Ecosystem delivers what modern marketing actually requires: speed, intelligence, and autonomy.
To learn more about how Blueshift powers real-time customer experiences, get in touch with our specialists.


